
The main problem with (traditional) synchronous code, is that processes hang while waiting for external data. Have you ever wondered “why do we need to provision yet another beefy AWS machine?” It may be because you’re not using your existing ones efficiently.
At Paxos, we think asyncio is python3’s killer feature. When we talk about python3, the first thing people usually ask is if they should switch to using it in their existing codebase. Here’s what we wrote in the past:
“With more python3 library support than python2, there’s no good reason to build a new app using python2. It makes sense to use asyncio if your app wastes a lot of cycles waiting on IO, is a good fit for an asynchronous framework (especially websockets), and resource intensive (reduce your server bill).”
Performance
When properly implemented, asyncio (with uvloop) can be very fast (link):
“uvloop makes asyncio fast. In fact, it is at least 2x faster than nodejs, gevent, as well as any other Python asynchronous framework. The performance of uvloop-based asyncio is close to that of Go programs.”
For example, in this cherry-picked benchmark, aiohttp had ~26x higher throughput (vs Flask):
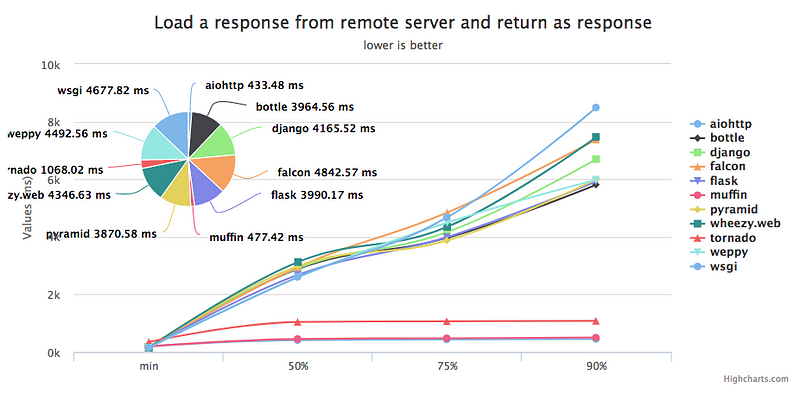
An Example
Suppose you have a simple website that is really just a visual wrapper for an API call. When a visitor loads your site, your server makes an external API call (say via HTTP), processes the results and serves them in pretty HTML. This API normally returns responses in < 50ms, and the server takes another 10ms to perform any business logic and render the HTML. So pages load in < 60 ms, and your end users are happy viewing your content.
Under normal circumstances, this will work sufficiently well for users. The only issue is that during those 50ms, the process remains blocked waiting on a response. No other code can be run by that process. So what happens if you get two requests at the same time? Any production server will route traffic to another worker (exactly how to do that routing is not so simple). As long as you have more workers available than requests, all your requests can be routed immediately and your users will remain happy. Pages will continue to load in < 60 ms.
Let’s say your site is running well with no changes, and you get on the front page of Hacker News. Suddenly, your pages are taking two seconds to load and you are trying to figure out what’s wrong. What happened? If you have more requests than workers available, requests will start to queue up waiting for available workers. You can find yourself in a situation where your processes are all individually sitting idle waiting for 50 ms API responses, and you have a queue backing up of new requests that are waiting for an available worker.
Alternatively, imagine that your site is running well with no changes and you don’t even have a spike in traffic, but pages start taking two seconds to load. You find that the API (that normally returns in ~50 ms) is having issues and starts returning in 500 ms. This is obviously bad for end users, as loading your webpage now takes a minimum of 510 ms to return. However, since threads will be blocked while waiting, your response times could be much slower than that. Your site will queue up lots of requests without any increase in load!
As you think through this example, it becomes obvious that it’s true for any heavy IO app. A slow external API call is no different from a slow database query.
Existing Solutions
This sounds like a big problem in the synchronous paradigm, as all of these blocked workers affect your bottom line. Companies pay money to have enough servers to serve requests quickly. Since blocked workers are unavailable to do other work, companies must increase their server budget to increase the number of workers available to pick up the slack.
In many cases, this solution works well enough. After all, most languages/frameworks are much easier to code in synchronously, and skilled developers are often much more expensive than hardware. In the words of Stack Overflow co-founder Jeff Atwood:
“Hardware is cheap, and programmers are expensive.”
However, as more solutions like node and asyncio make asynchronous programming easily accessible, more developers will learn to use these powerful tools.
How Asyncio Solves the Problem
With asyncio, your code is run inside an event loop. This means that when an API request is awaiting a response, control is returned back to the event loop. Instead of sitting idling by, another block of code (that’s not awaiting IO) can be executed. This effectively means you waste no CPU cycles while you await IO processes. For requests with high latency and/or high response times, these savings can be massive.
There are other solutions like using processes or threads, but these are much harder to manually manage.
Migrating
So, should you switch to an asynchronous framework?
Source: https://xkcd.com/1691/
When it comes to migrating a codebase, that’s a complicated task of weighing pros/cons and is unique to your situation. If you’re suffering from the problems above, you’d probably already know it.
Greenfield Projects
However, if you’re starting a new project where the cost of switching to an asynchronous framework is mostly just learning some new syntax, you should definitely check it out. Both aiohttp and sanic are very easy to get started, they even look a lot like Flask. You can check out this aiohttp hello world example here and this sanic hello world example here. This blog post contains lots of helpful code snippets.
Negatives
This sounds too good to be true! What are the drawbacks?
- Hard to use the interpreter (outside of event loop)
- Must use exclusively async code
- You have to think about the event loop
- Minor difficulties: fewer testing tools, less documentation, etc
We dicussed some of the other downsides previously on this post, but these things are all manageable and you should be on your feet in no time.
Conclusion
Asynchronous programming can increase your server efficiency to save you money, and asyncio makes it easy to do. Happy asynchronous programming!
Interested in working with these technologies (and more)? We’re hiring software engineers.
Originally published at www.paxos.com on October 12, 2017.