
How Aurora Blue-Green Upgrades Cut Our Postgres Downtime by 50X


Database maintenance is an important challenge for us given the high uptime expectations of always-on asset trading. Paxos powers regulated infrastructure that institutions and consumers rely on to move, convert, and hold assets 24/7 — so even planned downtime has real consequences for the people and businesses that trust us. Blue-Green upgrades have fundamentally changed how we approach it at Paxos. The complexity was real, especially around Temporary Roles and CDC, but the 50X downtime reduction and month of saved coordination made it worth it.
Customers were challenging us to think big about uptime: Does the downtime have to be every year? Can you achieve four nines all the time? Could you do a hot-cold failover to reduce impact?
The honest answer to all three questions was "not with our current approach." We were running 60+ Postgres clusters with traditional upgrade processes—30 to 120 minutes of downtime each.
Aurora Blue-Green upgrades promised to fix this. What I didn't anticipate from reading the docs is that CREATE ROLE statements involved in our Vault-based temporary roles for human logins would break every single upgrade attempt.
But, after dealing with DDL issues, working through how to not lose much data when replication slots drop, and grinding through a lot of databases, we now have a reusable pattern that keeps us up and meets our customer expectations.
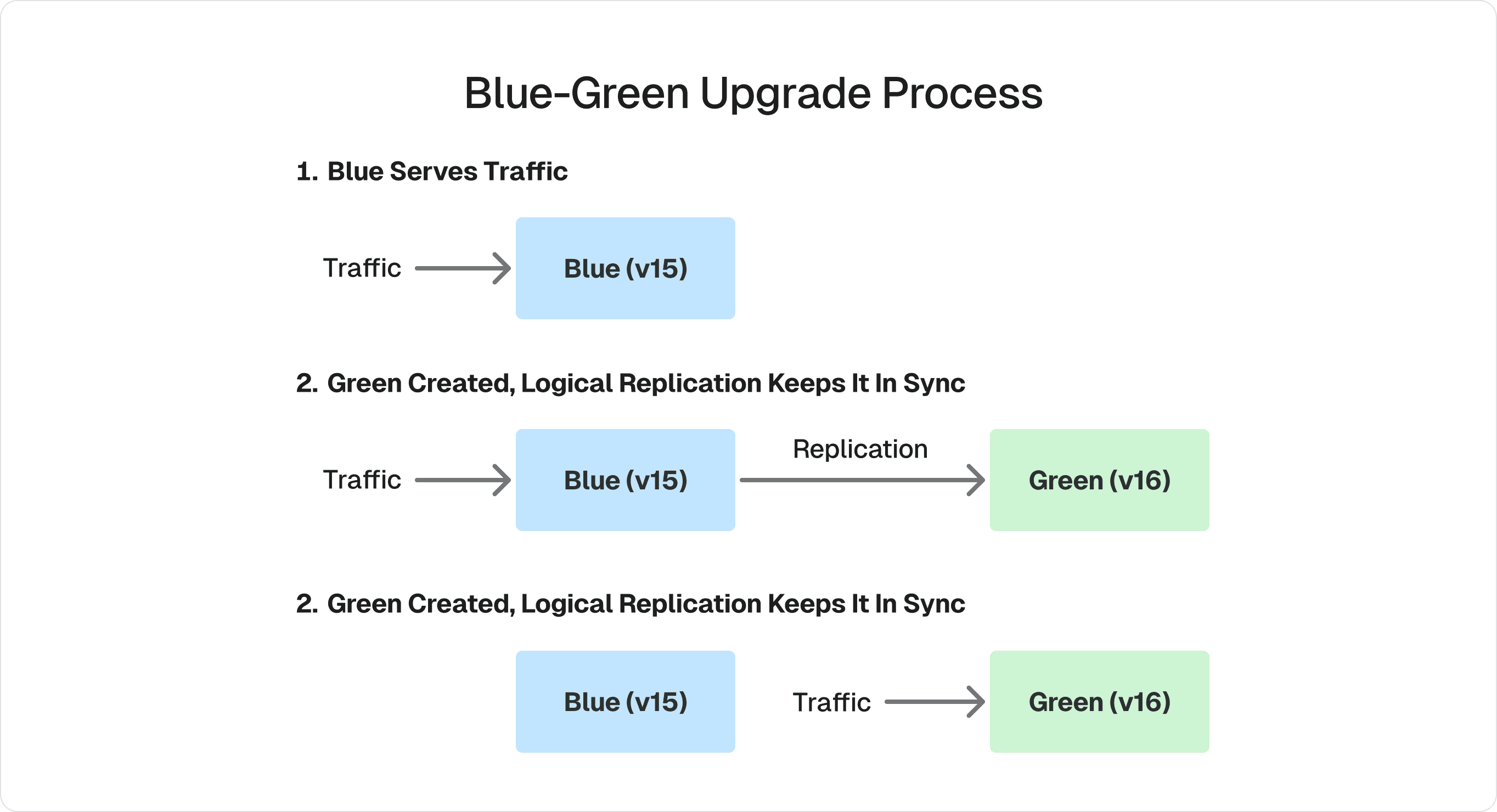
How Blue-Green Works
Instead of the traditional dump/reload or pg_upgrade process that takes your database offline, Blue-Green leverages PostgreSQL's logical replication to create a parallel environment. Your blue cluster keeps serving production traffic while a green cluster is created with the new version. Logical replication keeps them synchronized in real time. When replication catches up, the switchover happens in about a minute—writes pause briefly, everything syncs, and traffic moves to green.
For the full technical details, see AWS's Blue-Green documentation.
Challenges
Blue-Green upgrades are transformational, but they're not without friction. Here's what we ran into.
The Ephemeral Roles Trap
The first staging environment upgrade failed with an error saying DDL couldn't be replicated. I knew schema changes were off-limits during a Blue-Green upgrade—that's documented. But when I pulled down the actual Postgres logs from the AWS console, I found the culprit: a CREATE ROLE statement for a human trying to access the database.
We use Vault for temporary database credentials. Every time someone logs in to troubleshoot or run a query, Vault creates a short-lived role. That CREATE ROLE is DDL. And it breaks the upgrade.
I immediately realized this was going to be painful. We had to disable Vault-based role management entirely during upgrade windows and be much more careful about who accessed what. Even with those precautions, we hit retries on multiple clusters.
If you're using Vault or any dynamic role management system, deal with this before you start your upgrade project.
Replication Slots Must Drop (Pre-PG17)
This was the most significant challenge. Before PostgreSQL 17, replication slots must be dropped during a Blue-Green upgrade. If you're using Change Data Capture—and we rely heavily on it—this means data loss from the CDC perspective.
We use Debezium-based CDC for two critical purposes: replicating data to our warehouse, and powering event-driven workflows where database writes trigger downstream processing for API responses. When replication slots drop, we lose events during the gap. Recovering requires per-table, per-use-case backfill strategies that can take 3-30 hours per cluster to design and implement.
InstantDB wrote about hitting similar replication slot issues during their Postgres upgrade—they ultimately chose a different approach because of it. We decided to push through with Blue-Green and absorb the backfill cost, but it's the sharpest edge of this feature.
IAM Cluster IDs Change
When the green cluster becomes primary, it gets a new cluster ID. If you're using RDS IAM authentication, every client needs to be updated. This added 1-2 hours of work per cluster—not difficult, but it adds up across 60+ clusters.
The Results
Downtime dropped from 30-120 minutes per cluster to about one minute (roughly 50X improvement).
More importantly, this changed what's operationally possible. With traditional upgrades, we'd struggle to maintain 99.9% monthly uptime during maintenance periods. With Blue-Green, we can do upgrades without breaching 99.99% uptime SLOs on most products.
The customer coordination impact was equally significant. Hour-long downtimes meant weeks of coordination—meetings to review contingency plans, requests to reschedule, extensive documentation. Sub-five-minute downtimes reduced this to FYI notifications. Across 60+ clusters, that saved us at least a month of coordination work.
What's Coming: PostgreSQL 17
PostgreSQL 17 addresses our biggest pain point. Starting with upgrades from PostgreSQL 17, users don't have to drop logical replication slots. This means future upgrades (17 to 18, etc.) can preserve CDC continuity.
To be clear: our upgrades to PG17 still required dropping slots. But once you're on version 17, the path forward is much cleaner. This is a compelling reason to prioritize getting to PostgreSQL 17 if you rely on replication-slot-based CDC.
What I'd Tell Someone Starting This
Two things I wish I'd known:
Deal with Vault Auth first. Or at minimum, have a clean way to disable dynamic role creation during upgrade windows. The DDL sensitivity is documented, but the implication for Vault-based auth isn't obvious until it breaks your first upgrade.
Push AWS on replication slot support from readers. Being able to maintain CDC from a reader during the upgrade window would eliminate the backfill problem entirely. If enough customers ask for this, it might happen.
Infrastructure reliability isn't glamorous, but it's foundational to the trust that makes regulated digital assets work. If you're working through similar challenges with Postgres upgrades at scale, I'd be interested to hear what you've learned. You can reach me on LinkedIn.
Related Posts

Zero-Downtime Partitioning for a 21TB Postgres Table
