
Zero-Downtime Partitioning for a 21TB Postgres Table


We’re starting a series of posts about the real engineering challenges and tradeoffs behind what we ship—migrations, scale, reliability, and the sharp edges we hit along the way. If you like these kinds of problems, you might like working with us: Paxos Careers.
Partitioning a large Postgres table usually means rewriting millions (or billions) of rows. We had a 21TB ledger table nearing Aurora’s per-table size limit, and because crypto markets run 24/7, taking downtime wasn’t realistic—so we partitioned it with no backfill, no row movement, and a 371 ms cutover.
At Paxos, our ledger is backed by Postgres and is mission-critical – it can't go down, can't lose data, and can't fall behind. One of our most critical tables had grown to roughly two-thirds of Aurora’s per-table limit, with about a year of runway before writes would start failing. Even a brief planned outage would require heavy coordination and still risk customer impact, so the migration had to happen while the system kept running.
What partitioning unlocks
Avoiding the size ceiling was the immediate motivation, but partitioning also changes how the table behaves in a few important ways:
Faster writes. New rows land in a small "current" partition. Indexes stay smaller and vacuum has less work to do.
Archiving becomes a one-liner. Without partitions, removing history means long-running deletes that compete with live traffic. With partitions, archiving is
DETACH PARTITION.The size limit stops being a looming constraint. Partitions stay small and new data accumulates across multiple partitions instead of one ever-growing table.
The core idea: don't move history—relabel it
Instead of copying data into a new table, we built the partitioned structure around the existing one:
Create a new partitioned parent table.
Add a constraint to the existing table proving it belongs in a historical time range.
Attach the existing table as the “history” partition.
Create new time-range partitions for incoming data.
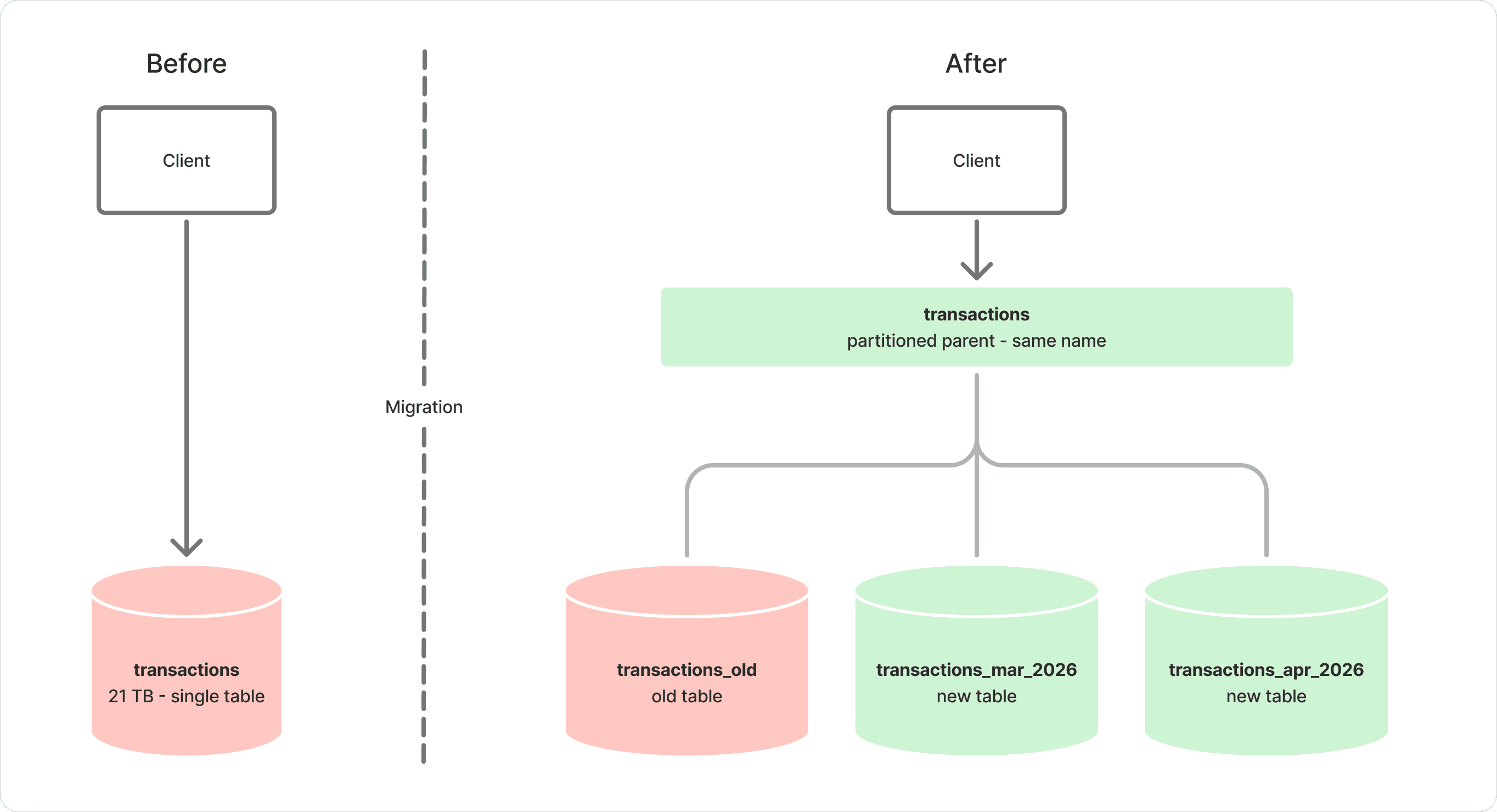
To callers, the table name stays the same. Under the hood, Postgres routes reads and writes based on the partition key.
How we made the cutover boring
1) The full table scan problem
When you attach an existing table as a partition, Postgres must prove every row satisfies the partition constraint. That proof is a full table scan. You can’t avoid the scan—but you can decide when it happens.
The trick: add the constraint as NOT VALID, then validate it ahead of time.
ADD CONSTRAINT ... NOT VALIDis fast and avoids scanning the table.VALIDATE CONSTRAINTdoes the scan later under aSHARE UPDATE EXCLUSIVElock. Reads and writes continue, but VACUUM/autovacuum can’t run on that table during the validation.
This is the step that converts the final cutover from “unknown duration” into a short, predictable transaction.
2) The timestamp chicken-and-egg
Partitioning by time is straightforward– until the partition key is set by a trigger.
Before partitioning, we relied on a BEFORE INSERT trigger to set the server-side timestamp used for ordering. Once that timestamp becomes the partition key, Postgres needs it up front to route the insert to the right partition.
A tempting workaround is to insert an approximate timestamp and “fix” it in a trigger. That doesn’t work: Postgres can’t move a row across partitions inside a BEFORE INSERT trigger. If the trigger shifts the timestamp over a partition boundary, the insert fails.
We solved this with a prepared database function: it chooses the timestamp, acquires the right locks, and performs the insert with the correct partition key. As a bonus, it gave us a single entry point to add idempotency checks.
Uniqueness and replay protection
Partitioning changes how uniqueness constraints behave. In Postgres, a UNIQUE constraint on a partitioned table can only be enforced globally if it includes the partition key. Otherwise, uniqueness is enforced per physical partition, which creates a subtle failure mode: two inserts with the same idempotency key can land in different partitions around a rollover and both succeed.
For a ledger, that’s unacceptable: it can apply the same logical transaction twice.
Instead of relying on partition-local uniqueness, we perform an idempotency check outside the balance-update lock to reduce contention. Uniqueness is still guaranteed because the idempotency decision is enforced by a single atomic insert. Once that succeeds, we acquire the balance-update lock and proceed. In internal validation, we measured less than 5 ms of added latency.
We shipped this ahead of the cutover so we could observe its latency profile before changing the schema.
Make it predictable: production-clone testing and "reverse history" load
Two kinds of tests mattered:
Correctness validation of the partitioned table
Performance/latency under realistic write load
Correctness validation
A cutover that “runs” but drops a trigger or changes a constraint is still a failure. Our tests explicitly verified:
Indexes exist and are valid on the new partitioned table.
Constraints and checks match expectations.
Triggers are recreated correctly on the new parent.
Sequences resume correctly, with no gaps or collisions.
Load and latency testing
A smaller test environment wasn’t enough: it didn’t have production-scale data, and repeatedly replaying a cutover on shared infrastructure was messy. Instead, we used Aurora production cloning to create a prod-sized database for safe testing.
To generate realistic load without triggering overdraft failures, we built a “reverse history” SQL generator: it reads real transaction history in reverse order and replays it back into the database. That preserves production-like distribution across accounts while avoiding the failure patterns hit when replaying history forward.
We benchmarked each change in isolation—the idempotency checks, the partitioned layout, and the full stack together. The goal wasn’t to make things faster; it was to confirm each step stayed within acceptable latency bounds before going to production.
What actually happened in production
The validation scan: nine hours of autovacuum starvation
On paper, VALIDATE CONSTRAINT is low impact: it holds a SHARE UPDATE EXCLUSIVE lock and allows reads and writes to continue. In practice, that lock also prevents VACUUM/autovacuum on the table for the duration of the scan.
On our first attempt, dead tuples accumulated with no vacuum to clean them up. Tail latency climbed steadily over hours, and eventually write spikes exceeded our timeout thresholds. Too many requests started failing, and we aborted.
On the second attempt, we planned for the degradation:
We coordinated with market makers to temporarily pause activity, since the trading path depends on low-latency balance updates and couldn’t tolerate the elevated tail latency.
We raised timeout thresholds so requests would complete—slower, but successfully.
The scan took just over nine hours. P50 stayed relatively flat, but P95/P99 climbed steadily as dead tuples built up. With market makers paused and timeouts relaxed, the system held.
In hindsight, this was the most operationally demanding part of the migration—not the cutover, but the scan that made the cutover possible.
The cutover itself: one short transaction
With validation complete and autovacuum caught up, the cutover became a single transaction that briefly holds an exclusive lock:
Lock the original table.
Rename it (it becomes the historical partition).
Create the new partitioned parent table.
Recreate indexes/constraints/grants and reuse the sequence.
Move triggers to the new parent.
Create a few current/future partitions.
Attach the renamed historical table as a partition.
Attach the historical indexes to the partitioned indexes.
After nine hours of watching dead tuple counts and tail latency graphs, the cutover itself took 371 milliseconds. Anticlimactic—exactly as designed.
What made this zero-downtime, in hindsight
We solved the hard problems before the cutover, not during it.
Complete the unavoidable scan ahead of time.
NOT VALID+VALIDATE CONSTRAINTturned the attach step into a scheduled scan. It wasn’t painless—nine hours without vacuum caused real tail-latency pain—but it was controlled and recoverable.Make the partition key explicit at insert time. A server-side function preserved ordering guarantees while meeting Postgres’s routing requirements.
Treat idempotency as a first-class migration concern. Partition boundaries are where invariants often break; we addressed replay protection up front and measured the latency impact.
Test on production-scale data. Aurora cloning and a reverse-history load generator gave us confidence we couldn’t get from staging.
If the outcome reads “simple,” that’s the point: we moved complexity out of the cutover moment and into controlled, testable steps. The result is a partitioned ledger table that still looks like “one table” to callers, while the physical layout can grow, age, and eventually be archived in pieces—without betting the platform on a maintenance window.
We do a lot of work like this at Paxos; if you want to follow along or get in touch, connect with us on LinkedIn.
